Ephemeral Environments
March 11, 2025
This note is a written version of a short presentation regarding Ephemeral Environments, a new approach for testing application releases at SemaphoreCI, where I've been working for the past 3 years.
A bit of a context
SemaphoreCI has existed for about 10 years, and the infrastructure we run our SaaS application on has evolved organically over that period. All of the app development, configuration, and testing was done with this specific infrastructure in mind.
When the decision to go open source was made, it became clear we would need to make changes to our code in order to decouple from our environment. That wouldn’t be a one-time thing where a few developers take a month and fix the issues that prevent our app from running on different infrastructure. We needed a system where we can continuously evaluate whether each new version of our app can run on all of the environments we support.
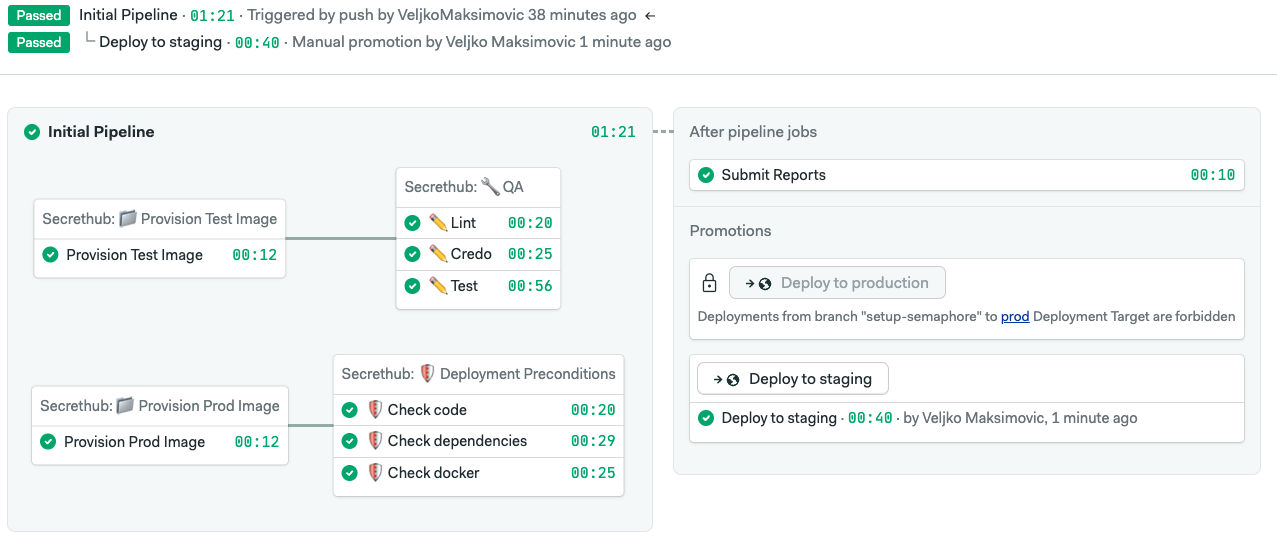
How our CI/CD looked before
We use a monorepo, and Semaphore allows us to selectively run jobs based on parts of the code that have changed. Then we build Docker images for services that have been updated, perform security scans and run tests. After that, the newly built images would be pushed to Google's Container Registry, the definition of our staging k8s cluster (k8s yaml manifests) would be automatically updated to use the new images, and voilà, you can test your changes.
What's the goal?
The idea is to migrate to something like this:
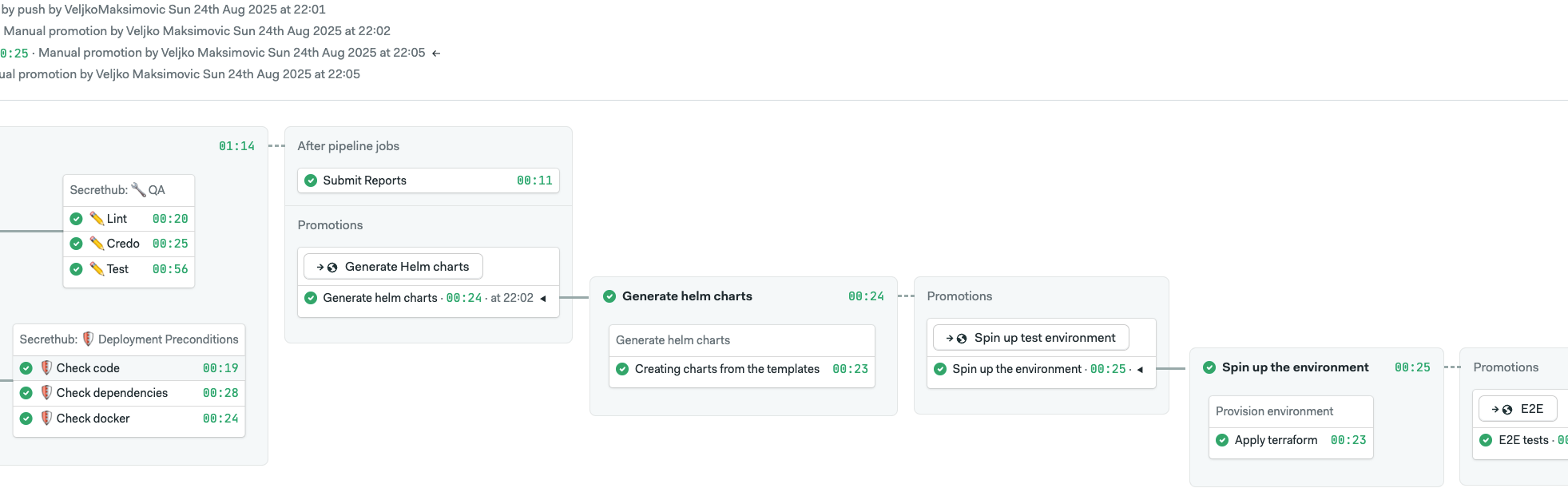
The first part is still the same, but now we package the app using Helm. After that, we need to provision clean infrastructure (ideally multiple types), install our app on all of them, run tests and then finally clean it all up.
So, how to implement that? Not sure yet. The only thing we knew from the start was that we would use Terraform for defining the infrastructure, since we already use it to manage our prod/staging environments. I decided to divide the project into 3 stages:
- Adapt existing terraform config (used for our staging) to manage the new GKE infrastructure which will be used for ephemeral environments.
- Once we validate that the new terraform works, integrate it into the CI pipeline.
- Lastly, once we have this setup working with GKE, let's try to adapt it to work with EKS as well
1) Making a minimal viable environment
Why not just use the same terraform we use for production/staging? Main reason: it is redundant. If you want to use Semaphore for yourself, a cheap, simple and easily maintainable environment beats all of the security measures, and additional compute capacity that is necessary for the production application.
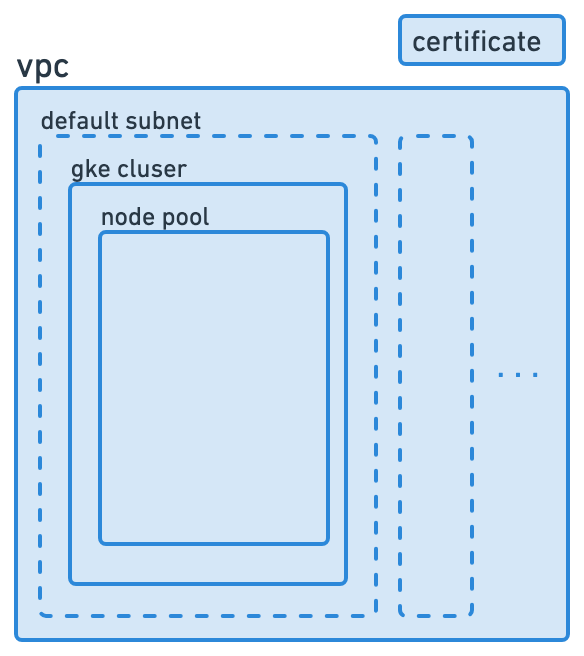
So, how much can we strip away? Turns out, a lot! In the production environment we have around 270 separate resources. There are a bunch of service level accounts and custom roles that follow the principle of least privilege, monitoring and alert policies, firewall rules, and so on. After removing all of that, we are left with only a few. If we explicitly list only the GKE resource in our Terraform, all related resources, such as the default VPC, subnet, and node pool will be created as well. Since Semaphore uses HTTPS, we will also need a google_certificate for validating incoming requests. That leaves us with the infrastructure that looks like this:
After the infrastructure has been spun up, we can install the app using helm install semaphore --var domain=mydomain.com. The app expects some values that are specific to the installation to be passed during the installation, and one of those values is the domain for the app.
During the helm installation we dont want to create new infrastructure resources, but rather just to populate the empty k8s cluster with resources (pods, mappings, services, etc.). One exception is Application Load Balancer. It is part of Google's infrastructure, not a k8s resource. Why did we not create this LB via Terafform, like other infrastructure resources?
GKE has something called "Google Cloud Ingress controller". It monitors k8s ingress definition, and automatically creates a LB if in the ingress.yaml we specify that we want to use Google's Application Load Balancer (which we do). The advantage of this approach is that the same controller will automatically destroy this Load Balancer if we uninstall our app, or modify it if we in the future change something in our ingress.yaml. Since the LB also performs TLS termination, we will point it to the certificate which was created during the infrastructure phase (terraform apply).
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: gce
ingress.gcp.kubernetes.io/pre-shared-cert: {{ $ssl.certName }}
spec:
...
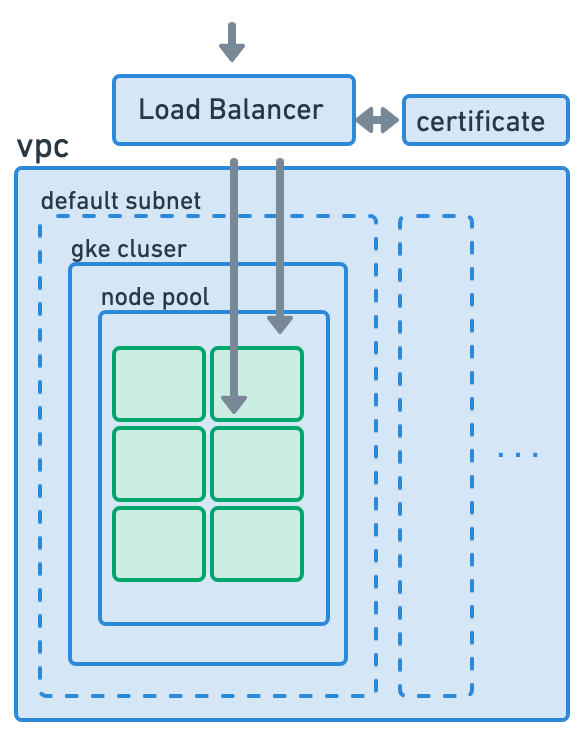
Now our environment looks something like this: We have all of the k8s pods running, LB can accept traffic, validate it, and redirect it to the desired k8s service.
We must set up DNS before the installation of our app
There is still one last problem "unique" to our application. For reasons that are out of scope for this blog, our helm install won't be done until one of the pods ("installation orchestrator") can ping itself via the domain it has been assigned (mydomain.com). Why is this an issue? Well in order for this orchestrator pod to be able to ping itself, we have to set up our DNS before we start helm install to point mydomain.com to the Load Balancer's IP, but, at that point in time Load Balancer does not exist (since it is being provisioned during helm install, as mentioned above), so we dont know to which IP we should point our domain. Thankfully, there is a Static IP resource in GCP. We can reserve an IP during the infrastructure provisioning phase (terraform apply), point our DNS to this IP (even though there is nothing attached to it), and then instruct Google Cloud Ingress controller to use this specific IP once it provisions the Load Balancer. That can be done by adding one more annotation to our ingress.yaml:
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: gce
ingress.gcp.kubernetes.io/pre-shared-cert: {{ $ssl.certName }}
kubernetes.io/ingress.global-static-ip-name: {{ $staticIpName }}
spec:
ingressClassName: {{ .Values.ingress.className }}
That's it! Step one complete, we have terraform configuration that will provision a simple environment, and we made changes to a few k8s manifests to work with this minimal environment!
2) Automate what was done until this point
Great, after a few hiccups we are done. I’ve manually validated that everything works, and we can move on to the second stage: Integrating this into our existing CI/CD workflow. This boiled down to:
- Pull the terraform configuration (which lives in a dedicated git repo)
- See if there is active terraform.tfstate (this will be the case if some infra was already provisioned, and we just want to update it)
- Run terraform init and terraform apply
- Once terraform resources are created, fetch the static ip from terraform outputs, and use it to update the DNS (point the domain to this ip)
- Finally, connect to the k8s cluster created in step 3, pull the Helm artifact, and run helm install Semaphor
Few caveats: Since all of the engineers will work on this monorepo, and they all need to run these ephemeral environments in parallel, we parametrized the terraform to take the name of the current git branch, and use it for naming all of the resources it creates, so there are no conflicts. The branch name is also used to generate the domain for each environment. We have a DNS that controls the domain semaphoretesting.com, and then each environment would get a subdomain, for example, fix-login-bug.semaphoretesting.com
3) Adapt the GKE terraform to work with EKS
Now, to move on to the last stage, setting up another testing environment (EKS). As an AWS novice, I was pretty sure EKS and GKE operate in more or less the same way. I could take the existing GKE terraform, give it to any of the AI tools, and tell it to adapt it for AWS. Was I in for a surprise.
The first issue I ran into: EKS forces your cluster to be spread over at least 2 subnets. Ok, that's an easy fix. After that, I had a running cluster I could use to install Semaphor, but none of the StatefulSets were being created… Turns out that by default, EKS clusters don't support persistent volume claims unless you explicitly enable the "EBS CSI Driver" addon. As a side note, while reading about this driver and how it works I stumbled upon this post:

At least I wasn't the only one who got stuck here :D v2 of the cluster created, new attempt to install Semaphor, and these StatefulSets are now working. Great! But, there are a bunch of other pods in the pending state, as if there are not enough resources on the machine to schedule their creation. I double-checked, and we were nowhere close to the CPU or the RAM limits. Well, another difference between GKE and EKS is how they assign addresses to the pods. Google uses IP aliases which do not limit the number of pods per machine, while Amazon uses something they call Elastic Network Interfaces - although the capacity of the interface is not elastic at all and has a hard limit of IP addresses it can assign to the machine. The machine we were using has a limit of 50, so we could either use a much bigger machine, or create another node in the pool, which is what we did.
Another round with a fresh environment, and installation fails again (timing out) even though all of the deployments are running successfully. After a bunch of debugging I narrowed it down to the ingress which probably wasn't set up properly. I did remember to change all the GCP specific annotations with their AWS counterparts. It looked like the ingress k8s object was created successfully, but there was no actual Application Load Balancer running. In the section above, regarding the GCP setup, I mentioned that once you create an ingress.yaml with proper annotations Google Cloud Ingress controller would pick that up and automatically spin up the Load Balancer. Amazon's Kubernetes engine does not do that by default. You need to install a special k8s controller called alb-controller before you start the installation process. The controller would then listen for ingress changes, and subsequently create the Load Balancer. During the creation of the EKS cluster, we will also tell terraform to install this controller so it can be ready once we decide to install Semaphor.
Ok, will this finally work?? Bear in mind, I've already been working on this EKS setup for like 4-5 days, even though I was sure it would take several hours at most.
Another round of terraform apply & helm install, Load Balancer is now created, but the installation is still timing out. As explained here, we need to configure DNS before we begin the installation process. Not a problem, we already solved this issue for GCP setup by reserving a Static IP, let's just do the same thing here.
If it were only that easy.
Turns out ALB doesn’t even use IP addresses directly, but rather some DNS alias that AWS would later map to an IP. And, you can't “reserve” a specific address name ahead of time, to use for DNS configuration.
This seemed like a dead-end. For several days I tried to move the creation of the Load Balancer from the helm install stage, to the terraform apply stage, so that we would know its address before we start the installation process, and we could set up our DNS properly. And then somehow tell the "alb-controller" to use this existing ALB instead of creating the new one. This is possible, and I saw someone doing this exact thing, but it seems like such a bad workaround. You have to match ALL metadata and labels between this ALB and ingress.yaml, and you also need to create security groups just to prevent k8s from deleting the LB later on. Thankfully, I stumbled upon another k8s controller called “external-dns”. If you give it permission to change your DNS (which was Route53 in our case), it can figure out the domain for your app from ingress.yaml annotations, wait for the load balancer to be created, and update your DNS to connect the domain with the load balancer.
Lo and behold, after a week of work and a bunch of head banging, our AWS ephemeral environment is finally working, and it looks something like this!
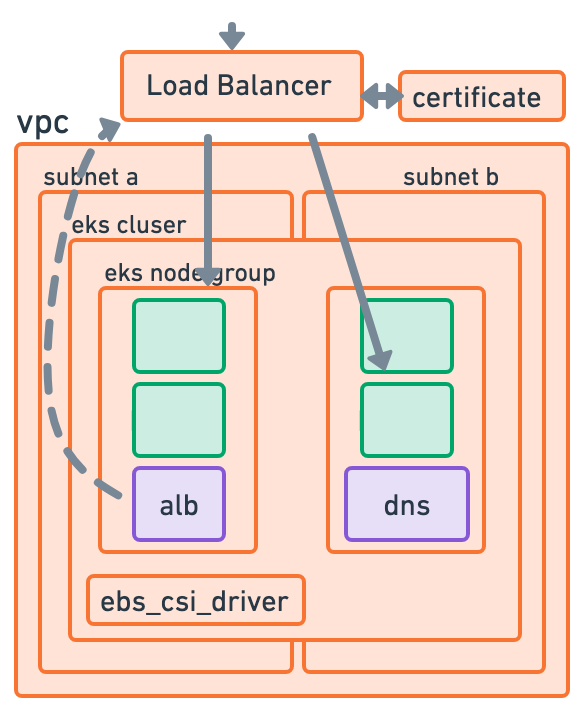
In turn, while waiting for me to finish this, another colleague created a third testing environment: A simple VM with k3s.
4) Conclusion
So, we changed our CI process significantly. Instead of pushing all of our changes to a singular staging environment, every developer spins up their own testing environment where they deploy and test their changes. One clear positive with this approach: you are sure no one else is testing their changes on your environment. This wasn't uncommon when we were using one staging. Also, since now we have several different environment types, once you are satisfied with the changes you made, you can spin up all of the different environments, and validate that the app still works on all of them.
Drawbacks
Testing data. On our current staging, which is always running, there is already a lot of data in the DB, so you can just go through the app and see how it behaves. In these clean environments there is no data, so you have to populate it first (create a few projects, a few workflows, git integrations, etc.) before testing out your feature. This could be sped up a lot if we had a script/database dump that would populate testing data each time a new testing environment is created.
Observability and Automation: These "ephemeral environments" aren't a resource Semaphore application recognizes. We create them, destroy them and manage them via a combination of terraform files, scripts, and artifact buckets. Hence, there is no UI page where we can go to, and see how many environments are currently running, who is using them, and how often. There is also no elegant way to automate their provisioning/deprovisioning, limit how many environments can be running in parallel, limit who can create new ones, etc.
There is a plan for us (Semaphore team) to actually dedicate some time to tackle this issue. We want to support ephemeral environments as "first-class citizens" in our app, so they can be easily utilized by other organizations as well. If that happens, there will hopefully be another post on this blog explaining the process we went through, and how it works "under the hood".
Glossary
- Elastic Kubernetes Service(EKS)
- Amazon's managed Kubernetes service for running Kubernetes without installing or maintaining your own control plane
- Google Kubernetes Engine(GKE)
- Kubernetes service offered by Google Cloud Platform for deploying containerized applications
- Helm(HELM)
- A package manager for Kubernetes that helps you define, install, and upgrade applications
- k3s(k3s)
- Lightweight Kubernetes alternative
- Kubernetes(k8s)
- A container orchestration system for automating software deployment, scaling, and management
- Terraform(TF)
- An infrastructure as code tool that lets you build, change, and version infrastructure safely and efficiently